Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
An introduction to the Parallel Virtual File System and a look at how one company installed and tested it.
Using networked file systems is a common method for sharing disk space on UNIX-like systems, including Linux. Sun was the first to embrace this technology by introducing the Network File System (NFS), which provides file sharing via the network. NFS is a client/server system that allows users to view, store and update files on remote computers as though they were on the user’s own computer. NFS has since become the standard for file sharing in the UNIX community. Its protocol uses the Remote Procedure Call method of communication between computers.
Using NFS, the user or a system administrator can mount all or a portion of a file system. The portion of your file system that is mounted can be accessed with whatever privileges accompany your access to each file (read-only or read-write).
As the popularity and utility of this type of system have grown, more networked file systems have appeared. These new systems include advances in reliability, security, scalability and speed.
As part of my responsibilities in the Systems Research Department at Ericsson Research Canada, I evaluated Linux-networked file systems to decide what networked file system(s) to adopt for our Linux Clusters. At this stage, we are experimenting with Linux and clustering technologies and trying to build a Linux cluster that provides extremely high scalability and high availability.
An important factor in building such a system is the choice of the networked file system(s) with which it will be used. Among the tested file systems were Coda, Intermezzo, Global File System (GFS), MOSIX File System (MFS) and the Parallel Virtual File System (PVFS). After considering these and other options, the decision was made to adopt PVFS as the networked file system for our test Linux cluster. We are also using the MOSIX file system as part of the MOSIX package (see Resources) that enhances the Linux kernel with cluster-computing capabilities.
In this article, we cover our initial experiences with the PVFS system. We first discuss the design of the PVFS system in order to help familiarize readers with the terminology and components of PVFS. Next, we cover installation and configuration on the 7 CPU Linux Cluster at the Ericsson Systems Research Lab in Montréal. Finally, we discuss the strengths and weaknesses of the PVFS system in order to help others decide if PVFS is right for them.
PVFS Overview and Goals
Linux cluster technology has matured and undergone many improvements in the last few years. Commodity hardware speed has increased, and parallel software has become more advanced. Input/Output (I/O) support has traditionally lagged behind computational advances, however. This limits the performance of applications that process large amounts of data or rely on out-of-core computation.
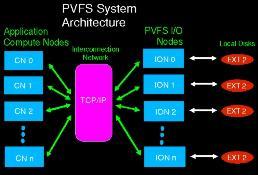
Figure 1. PVFS System Architecture
PVFS was constructed with two main objectives. The foremost is to provide a platform for further research into parallel file systems on Linux clusters. The second objective is to meet the growing need for a high-performance parallel file system for such clusters. PVFS goals are to:
- Provide high bandwidth for concurrent read/write operations from multiple processes to a common file
- Support multiple APIs, including a native PVFS API, the UNIX/POSIX I/O API, as well as MPI-IO (through ROMIO)
- Support Common Unix utilities such as ls, cp and rm for PVFS files
- Provide a mechanism for applications developed for the UNIX I/O API to work with PVFS without recompiling
- Offer robustness and scalability
- Be easy to install and use
PVFS Node Types
One machine, or node, in a cluster, can play a number of roles in the PVFS system. A node can be thought of as being one or more of three different types: compute, I/O or management. Typically, a single node will serve as a management node, while a subset of the nodes will be compute nodes and another subset will serve as I/O nodes. It is also possible to use all nodes as both I/O and compute nodes.
PVFS exists as a set of dæmons and a library of calls to access the file system. There are two types of dæmons, management and I/O. Typically, a single-management dæmon runs on the management node and a number of I/O dæmons run on the I/O nodes. The library of calls is used by applications running on compute nodes, or client nodes, in order to communicate with both the management dæmon and the I/O dæmons.
Management and I/O Dæmons
Management dæmons, or managers, have two responsibilities: validating permission to access files and maintaining metadata on PVFS files. All of these tasks revolve around the access of metadata files. Only one management dæmon is needed to perform these operations for a file system and a single-management dæmon can manage multiple file systems. The manager is also responsible for maintaining the file system directory hierarchy. Applications running on compute nodes communicate with the manager when performing activities such as listing directory contents, opening files and removing files.
On the other hand, I/O dæmons serve the single purpose of accessing PVFS file data and correlating data transfer between themselves and applications. Direct connections are established between applications and I/O servers in order to directly exchange data during read and write operations.
Accesses to Client Nodes
There are several options for providing PVFS access to the client nodes. First, there is a shared, or static, library that can be used to interact with the file system using its native interface. This requires writing applications specifically to use functions such as pvfs_open, however. As an alternative, there are two access methods that provide transparent access. The preferred method is to use the PVFS kernel module, which allows full access through the Linux VFS mechanism. This loadable module allows the user to mount PVFS just like any other traditional file system. Another option is to use a set of C library wrappers that are provided with PVFS. These wrappers directly trap calls to functions such as open and close before they reach the kernel level. This provides higher performance but with disadvantages in that the compatibility is incomplete, and the wrappers work only with certain supported versions of glibc.
A final option is to use the MPI-IO interface, which is part of the MPI-2 standard for message passing in parallel applications. The MPI-IO interface for PVFS is provided through the ROMIO MPI-IO implementation (see Resources) and allows MPI applications to take advantage of the features of MPI-IO when accessing PVFS. It also ensures that the MPI code will be compatible with other ROMIO-supported parallel file systems.
Installation Environment
The test system at Ericsson Montréal started as a cluster of seven diskless Pentium grade CPUs with 256MB of RAM each. These CPUs first boot using a minimal kernel written on flash using a tool provided by the manufacturer. They then they get their IP address and download a RAM disk from a Linux box acting as both a DHCP and a TFTP server. This same machine also acts as an NFS server for the CPUs, providing a shared disk space.
When we decided to experiment with PVFS, we needed some PCs with disks to act as I/O nodes and one PC to be the management node. We added one machine, PC1, to be the management node and three machines, PC2, PC3 and PC4, with a total disk space of 35GB, to be the I/O nodes. The new map of the cluster became:
- Seven Diskless Client CPUs
- One Management Node
- Three I/O Nodes
Installation Steps
While PVFS developers provide RPMs for all types of nodes, we chose to recompile the source in order to optimize installation on the diskless clients. This went over without a hitch using the PVFS tarball package. For the manager and I/O nodes, we used the relevant RPM packages. The manager and I/O nodes are using the Red Hat 6.2 distribution and the 2.2.14-5.0 kernel. The diskless CPUs run a customized minimal version of the 2.2.14-5.0 kernel.
Setting up the Manager
The first step towards setting up the PVFS manager is to download the PVFS manager RPM package and install it. PVFS will be installed by default under /usr/pvfs. Once the automatic installation is done, it is necessary to create the configuration files. PVFS requires two configuration files in order to operate: “pvfsdir”, which describes the directory to PVFS and “iodtab”, which describes the location of I/O dæmons. These files are created by running the mkiodtab script (as root):
[root@pc1 /root]# /usr/pvfs/bin/mkiodtab
See Listing 1 for the iodtab setup for the Parallel Virtual File System. It will also make the .pvfsdir file in the root directory.
Listing 1. iodtab Setup for the Parallel Virtual File System
Enter the root directory: /pvfs
Enter the user id of directory: root
Enter the group id of directory: root
Enter the mode of the root directory: 777
Enter the hostname that will run the manager: pc1
Searching for host...success
Enter the port number on the host for manager:
(Port number 3000 is the default) 3000
Enter the I/O nodes: (can use form node1, node2, ... or
nodename{#-#,#,#})
pc2,pc3,pc4
Searching for hosts...success I/O nodes: pc2,pc3,pc4
Enter the port number for the iods:
(Port number 7000 is the default) 7000
Done!
[root@pc1 /root]#
When we ran mkiodtab on the manager, PC1, it complained that it did not find the I/O nodes. It turned out to be that we had forgotten to include entries of my I/O nodes in /etc/hosts. We updated the /etc/hosts file and reran mkiodtab; everything went okay. mkiodtab created a file called “iodtab” under /pvfs. This file contained the list of my I/O nodes. It looked like the following:
------------/pvfs/.iodtab------------ pc2:7000 pc3:7000 pc4:7000 -------------------------------------
The default port number used by I/O dæmon software to allow clients to connect to it over the network is 7,000.
After running mkiodtab, we did the following to start PC1 as the PVFS manager:
Start the manager dæ: % /usr/pvfs/bin/mgr % /usr/pvfs/bin/enablemgr
Running enablemgr on the management node ensures that the next time the machine is booted the dæmons will be automatically started, so that it doesn’t need to be started manually after rebooting. The enablemgr command only needs to be run once to set up the appropriate links.
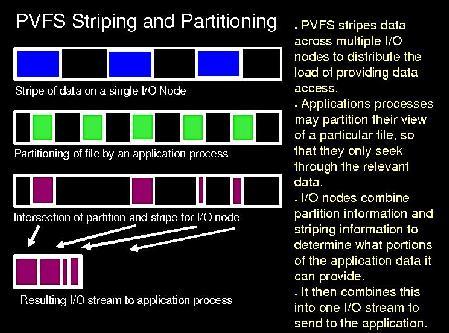
Figure 2. PVFS Striping and Partitioning
Setting up the I/O Nodes
Installation of I/O nodes is equally simple. First, we installed the RPM, then started each I/O dæmon as follows:
% /usr/pvfs/bin/iod % /usr/pvfs/bin/enableiod
Running enableiod on the I/O nodes ensures that the next time the machines are booted, the dæmons will be started automatically. The enableiod command only needs to be run once to set up the appropriate links.
The I/O dæmons rely on a configuration file, /etc/iod.conf, to tell them where to store data. This file is automatically created by the RPM and directs the I/O dæmons to store data in a directory called /pvfs_data. We created this directory on each of the I/O nodes with:
% mkdir /pvfs_data
Setting up the Diskless CPUs as Compute Nodes
The installation of the client CPUs was more delicate since, as mentioned above, we needed to minimize the installation to use less space on the RAM disk. The minimal set of installation files that we used for the client nodes were:
------------ List of files installed on the Compute Nodes ------------- /etc/pvfstab /usr/local/pvfs/pvfsd /usr/local/pvfs/pvfs.o /usr/local/pvfs/mount.pvfs /usr/local/pvfs/libpvfs.so.1.4 -------------------------------------------------------------------------
The /etc/pvfstab is used by the compute nodes to determine the locations of the manager and the PVFS files. Its format is very similar to the /etc/fstab file. For our setup, the /etc/pvfstab file looked like the following:
----------------/etc/pvfstab-------------------- pc1:/pvfs /pvfs pvfs port=3000 0 0 ------------------------------------------------
This configuration file specified that:
- The management node is PC1
- The directory where the manager is storing metadata is /pvfs
- The PVFS file system is mounted on /pvfs on the client
- The port on which the manager is listening is 3000
The PVFS dæmon is /usr/pvfs/bin/pvfsd. It works in conjunction with the kernel module to provide communication with the file system through the kernel. The dæmon uses the same PVFS library calls that a custom user application would, but it translates them into a form recognized by the kernel module so that it is hidden from applications not specifically compiled for PVFS. This is similar to the approach used by the Coda file system in which a user-level dæmon cooperates with the Coda kernel code to access the file system (see Resources)./usr/pvfs/bin/mount.pvfs is the special mount command supplied with PVFS. The client CPUs use it to mount the PVFS file system on a local directory. For these CPUs, we have created a small shell script, /etc/rc.d/rc.pvfs, that is executed when the CPUs are started to ensure that they start up automatically as PVFS compute nodes without any manual intervention. The content of rc.pvfs is the following:
-----------------/etc/rc.d/rc.pvfs------------------ #!/bin/sh /bin/mknod /dev/pvfsd c 60 0 /sbin/insmod /usr/pvfs/bin/pvfs.o /usr/pvfs/bin/pvfsd /usr/pvfs/bin/mount.pvfs pc1:/pvfs /mnt/pvfs ----------------------------------------------------
The script creates a node in /dev that will be used by pvfsd. It loads the PVFS module, starts the PVFS dæmon and mounts the PVFS file system locally under /mnt/pvfs.
As noted earlier, any I/O node or management node can also serve as a compute node. To enable this, we simply installed the PVFS client RPM on each I/O node, as we are not worried about conserving disk space on the I/O nodes. The /etc/pvfstab and /etc/rc.d/rc.pvfs were then set up to be identical to those used on the diskless clients. Now, both the diskless clients and the I/O nodes can access the file system in the same manner.
Testing the Installation
After completing these installation steps we were able to copy and access files within the PVFS file system from all of the machines. The RAM disk that was installed on the CPUs included as part of the setup the Apache Web Server and Real Server, a video streaming server from Real Networks. We used WebBench (from ZDNet.com) to generate web traffic to the CPUs and changed the configurations for both Apache and Real Server to place the default root document inside the PVFS file system. This scenario allowed every CPU to run as a stand-alone web server with its own IP address and serve multimedia requests using Real Server. This allowed hosting web files, including big files such as mp3 and rm files, from within the PVFS file system.
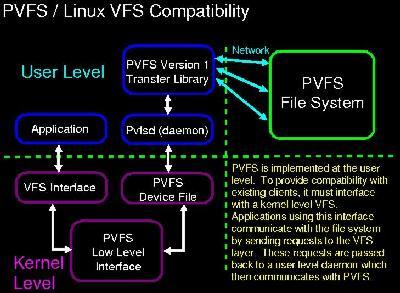
Figure 3. PVFS/Linux Compatibility
Coexistence with Other File Systems
As certain types of applications perform better on certain file systems due to their access patterns, it is important to us that PVFS be able to coexist with other file systems. The PVFS system had no problem operating in the same environment with JFS, NFS, SFS and even the MOSIX file system. This neat setup served large I/O requests such as mp3 files on the Web. The MOSIX file system was used by MOSIX to migrate processes on the cluster to the most appropriate CPU at the time.
Typically, PVFS sits on top of the ext2 file system. However, the next generation of Linux file systems will be journaling file systems. This protects against hardware or software failures by producing a log of changes-in-progress that records changes to files and directories in a standard way to a separate location, possibly a separate disk. If the primary file system crashes, the journal can be used to undo any partially completed tasks that would leave the file system in an inconsistent state.
The next step in this perspective is to see how well PVFS performs on top of ext3 and GFS as native file systems. This is left for experimentation on the new cluster (see below).
Scaling up the Installation
Another important factor in choosing a file system such as PVFS is to check how well it can scale up with more client and I/O nodes. Having one nonredundant management node might seem like an inherent bottleneck. However, the manager is not involved in any read or write operations, as these are handled directly between clients and I/O dæmons. It is only when many files are created, removed, opened or closed in rapid succession that the manager is heavily loaded.
We wish to test the scalability of this configuration, however so the upcoming PVFS installation will be on a cluster consisting of 16 PIII 500 MHz CPUs with 512MB RAM each. Eight of the CPUs have 18GB SCSI disks each with a mix of RAID 1 and RAID 5 setup. The projected installation will have one Manager, seven I/O nodes and 14 clients (I/O nodes are also clients). This cluster will allow us to better understand how PVFS will scale for our applications and will additionally allow us to compare PVFS performance with the performance of alternative file systems, such as NFS, for systems of this size. Tests of PVFS on other clusters have shown it to be scalable to systems of more than 64 nodes for other workloads. (See “PVFS: A Parallel File System for Linux Clusters” at PVFS’s web site in Resources.)
PVFS Advantages
PVFS is easy to install and configure. It comes with an installation guide that walks administrators through the installation procedure. It provides high performance for I/O intensive parallel or distributed applications. It is also compatible with existing applications so that you don’t have to modify them to run with PVFS. PVFS is well supported by the developers through mailing lists.
PVFS Vulnerabilities
PVFS currently contains neither data redundancy nor recovery from node failure. There may also be potential bottlenecks at the manager level as the number of client nodes increases. PVFS endures restrictions introduced by TCP/IP dependence, such as limits on the number of simultaneous open system sockets and network traffic overhead inherent in the TCP/IP protocol. As for security, PVFS provides a rather unsophisticated security model, which is intended for protected cluster networks. Also, for the time being, PVFS is limited to the traditional Linux two gigabyte file size.
Types of applications that benefit the most from PVFS are:
- Applications requiring large I/O, such as scientific computation or streaming media processing
- Parallel applications because the bandwidth increases as multiple clients access data simultaneously
Types of applications for which PVFS is poorly suited:
- Applications requiring many small, low-latency requests, such as static html pages (there is quite a bit of overhead in network traffic for multiple small file requests)
- Applications requiring long-term storage or failover ability—PVFS does not provide redundancy on its own
Writing PVFS Programs
As noted earlier, existing applications can access PVFS through either the kernel module or the library wrapper interface. This does not require any modification from the user’s point of view. However, to obtain the best performance for parallel applications, developers must modify their applications to use a more sophisticated interface. There are two options for this approach as well. The first is to use the native PVFS library calls. This interface allows advanced options, such as specifying file striping and number of I/O nodes. It also lets each process define a “partition” or particular view of the file so that contiguous read operations access only specific offsets within the file (see Figures 2 and 3). Documentation for this is available in the PVFS user’s guide.
MPI-IO is the preferred option for writing PVFS programs. It layers additional functionality on top of PVFS, including collective file operations and two phase I/O. This interface is documented as part of the MPI-2 standard.
Security Issues
As mentioned before, PVFS does not implement many security features at this time. It is primarily intended for use on private cluster networks that can insure trusted clients. There is no restriction on client connections, nor is there any encryption or keys used to verify user authenticity. Client nodes are generally trusted to provide accurate UID information for use in file permissions and ownership checks, just as in NFS.
The Future of PVFS
There are many changes and advances in store for PVFS. The existing generation of PVFS is undergoing modifications and testing to support a higher degree of scalability. These mostly address issues with supporting large numbers of TCP/IP sockets. They will also resolve the issues inherent in supporting 64-bit (greater than two-gigabyte) file sizes and offsets. This will allow PVFS to scale to the current size of large-scale clusters that utilize hundreds or thousands of nodes.
PVFS as a whole is undergoing a full redesign at the same time. This will result in a complete rewrite of PVFS that incorporates new technology and lessons learned from the previous implementation. This version of PVFS will not be available for quite some time but is already in active development.
Some of the features that will be supported in the next generation are:
- Reactive scheduling that allows PVFS to adapt policies based on system state and application load
- Modular support for a variety of networking systems, so that the file system is no longer bound to TCP/IP but can take advantage of more advanced messaging protocols as they become available
- Modular support for a variety of storage methods to allow I/O dæmons to access local data through various methods, such as raw I/O or asynchronous I/O
- Multiple manager support
- Redundancy of both I/O data and metadata in case of system failure
- Improvements in the UNIX compatibility layer
- More advanced options for data distribution as well as data representation
After evaluating several distributed file systems, we chose to use PVFS for applications that require intensive I/O. PVFS, in its current state, does not provide any redundancy or high security features. However, the research is still ongoing, and we have high hopes in this regard. We believe that if PVFS were to provide access security, data redundancy and management node redundancy, then it would be more suitable for adoption as part of a highly scalable, reliable and fault-tolerant Linux cluster. As it stands now, however, it is more suited for application domains (such as scientific computing) in which optimal performance is paramount rather than high availability.
I had a pleasant experience with PVFS and with the developers who provided a lot of help as we achieved the above setup and contributed much to the writing of this article.
If you are interested in distributed file systems and you need support for high-performance I/O, I highly recommend that you try out PVFS. PVFS is freely available under the GPL and can be downloaded from Clemson University’s web site (see Resources).
Acknowledgments
Primary PVFS developers: Robert Ross, Mathematics and Computer Science Division, Argonne National Lab. Philip Carns and Walt Ligon, Parallel Architecture Research Lab, Clemson University, with support from NASA’s Goddard Space Flight Center as well as Argonne National Lab. Ericsson Research Canada: The Systems Research Department at Ericsson Research Canada for providing the facilities and equipment as well as approving the publication of this article.
Contributors
Philip Carns (pcarns@hubcap.clemson.edu) is a graduate student at the Parallel Architecture Research Lab at Clemson University. Robert Ross (rross@mcs.anl.gov) is employed at the Argonne National Laboratory by the Mathematics and Computer Science Division. He will receive his Doctoral degree in Computer Engineering from Clemson University in December 2000.
Ibrahim F. Haddad (ibrahim.haddad@lmc.ericsson.se) works for Ericsson Research Canada in the Systems Research Division. He is currently a DrSc candidate in Computer Science at Concordia University in Montréal.