Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
Linux, Linux OS, Free Linux Operating System, Linux India Linux, Linux OS,Free Linux Operating System,Linux India supports Linux users in India, Free Software on Linux OS, Linux India helps to growth Linux OS in India
A look at current state-of-the-art network hardware and protocols with a solution for the slow network problem.
We have been using Linux to develop a new high-speed network we call FlowNet. This project has been a “virtual garage” operation, involving only two people, one in California and the other (at various times) in Massachusetts, Pennsylvania and Indiana. We transferred designs and code over the Internet and hardware via Federal Express. The result is a unique network that combines the best features of today’s current standards into a single design. FlowNet is currently the world’s fastest computer network capable of operating over 100 meters of standard category-5 copper cable. The software for FlowNet was developed and currently runs exclusively under Linux.
To appreciate how FlowNet works, it is important to understand some details about network hardware, so we will start with a brief tutorial on the current network state of the art.
Network Background
The dominant hardware standard for local area networks today is Ethernet, which comes in dozens of variants. The only feature common to all forms of Ethernet is its frame format; that is, the format of the data handled directly by the Ethernet hardware. An Ethernet frame is a variable-size frame ranging from 64 to 1514 bytes, with a 14-byte header. The header contains only three fields: the address of the sender of the frame, the address of the receiver and the frame type.
Shared-Media Ethernet
Ethernet design has two major variations called shared-media and switched. In shared-media Ethernet, all the network nodes are connected to a single piece of wire, so only one node can transmit data at any one time. Ethernet uses a protocol called carrier-sense-multiple-access with collision detection (CSMA/CD) to choose which node is allowed to transmit at any given time. CSMA/CD is a non-deterministic protocol and does not guarantee fair access. In fact, in a heavily congested network, CSMA/CD tends to favor a single node to the exclusion of others, a phenomenon known as the capture effect. Being on the wrong end of the capture effect is one way a network connection can be lost for a long period of time.
The CSMA/CD protocol does not allow a node to start transmitting while the wire is being used by another node (that is the carrier-sense part). However, it is possible for two nodes to start transmitting at almost the same time. The result is that the two transmissions interfere with each other and neither transmission can be properly received. The period during which a collision can occur is the time from when a node starts to transmit to when the signal actually arrives at all other nodes on the wire. This time depends on the physical distance between the furthest nodes on the wire. If this distance is too long, a node might finish transmitting a frame before it arrives at all nodes on the wire. This would make it possible for a collision to occur that the transmitting node would not detect. In order to prevent this from happening, the physical span of a shared-media Ethernet network is limited. This distance is known as the collision diameter; it is a function of the time necessary to transmit the shortest possible Ethernet frame (64 bytes). The collision diameter of a traditional Ethernet operating at 10Mbps is about two kilometers, which is plenty for most local area networks. However, the collision diameter shrinks at faster data rates, since the time it takes to transmit a frame is less. The collision diameter for Fast Ethernet, which operates at 100Mbps, is 200 meters—a limit that can be constraining in a large building. (The collision diameter for Gigabit Ethernet would be 20 meters, but because this distance is so ridiculously short, Gigabit Ethernet does not use CSMA/CD.)
Switched Ethernet
The way to get around the limitations of shared-media Ethernet is to use a device called a switch. A switch has a number of connections or ports, each of which can receive a frame simultaneously with the others. Thus, in a switched network, multiple nodes can transmit at the same time. In a purely switched network, every node has its own switch port and there can be no collisions. However, there can still be resource contention because it is now possible for two nodes to simultaneously transmit frames destined for a single node, which still can receive only one frame at a time. The switch must therefore decide which frame to deliver first and what to do with the other frame while waiting. Switches typically include some buffering so that contention of this sort does not necessarily result in lost data, but under heavy use, all switched networks will eventually be forced to discard some frames.
How does the switch decide which frames to drop? Most switches simply operate on a first-in/first-out basis. That is, when they are forced to drop frames, they drop the most recently received ones. Not much in the way of alternatives is offered because no information is in the Ethernet header to indicate which frames are less important and should be dropped first. As a result, when most switches become congested, they drop frames essentially at random.
That behavior creates a serious problem. The response of most network protocols, including TCP/IP, to dropped frames is to retransmit the dropped frames. Thus, network congestion leads to randomly dropped frames, which leads to retransmission, which leads to more network congestion, which leads to more randomly dropped frames. When this happens, many networks, in particular the Internet, will often come to a screeching halt.
Quality of Service
The only way to solve this problem is to add information to the frame to give switches guidance on how to handle individual frames. For example, if a frame is tagged as part of an e-mail message, a switch would know that it is perfectly acceptable to delay this frame, but also that it should probably not be discarded. On the other hand, if this frame is part of a video stream, then a switch would know that if this frame cannot be transmitted right away, it should be discarded, resulting in a small glitch in the video. Information on how a frame should be handled in a congested network is known as quality-of-service information or QoS.
QoS information can be provided in three ways. The first is to completely redesign the network from the ground up. This is the approach used by the Asynchronous Transfer Mode (ATM) network design. ATM is a circuit-switched rather than a packet-switched network. In a packet-switched network like Ethernet, each data frame contains its destination address in its header. The process of delivering a frame to its destination is similar to that of delivering a letter. At every switch, the destination address is looked up in a table to see where it should go next. Circuit-switched networks like ATM put the destination address into only one frame, called a flow-setup frame or flow-setup cell. The flow-setup cell establishes a route through the network, much like placing a phone call does. Subsequent frames are automatically routed through this pre-established connection. The flow-setup process allows the ATM network to allocate network resources ahead of time in order to provide quality-of-service guarantees.
ATM’s circuit-switched design is fundamentally incompatible with Ethernet’s packet-switched design. ATM also differs from Ethernet in the size of its frames. Where Ethernet uses variable-size frames, ATM uses fixed-size 53-byte frames or cells, of which five bytes are header and 48 bytes per frame are payload data. This leads to a serious problem: the rate at which cells must be routed is so fast that it can be done only with custom hardware, which makes ATM very expensive.
The second way to provide QoS information is to put it in the data portion of an Ethernet frame. This is the approach being taken by the Ethernet community, through protocols such as RSVP. The advantage to this approach is that it is backwards compatible with existing hardware, which is important because an enormous Ethernet infrastructure is already installed. ATM can be made to interoperate with Ethernet through a technology called LAN emulation (LANE), but it is both difficult and inefficient.
The problem with implementing QoS using the existing Ethernet frame format is that most existing hardware will not recognize the new protocols associated with QoS. This can undermine the QoS mechanisms by injecting frames into the network which are not properly tagged or by not handling tagged frames properly. Thus, while this approach is backwards compatible with existing hardware, it probably won’t be reliable unless most of the existing infrastructure is replaced.
The third approach is to add QoS information to the Ethernet header. This is a non-backwards-compatible change, but not as radical a redesign as ATM, and it can be done in a way that makes it easy to interoperate the new network with existing hardware. This is the approach we have taken in the design of FlowNet.

Figure 1. The FlowNet prototype is built entirely from off-the-shelf components and fits in a standard PCI slot just like an Ethernet card. In production, this board could be reduced to just two or three chips.
The FlowNet Architecture
Like ATM, FlowNet is a switched network based on fixed-size cells. Unlike ATM, FlowNet cells are large—800 bytes instead of 53. This allows room for a 14-byte Ethernet header plus an additional QoS extension. The QoS extension header is 18 bytes, making the full FlowNet header 32 bytes long. The remaining 768 bytes (=256+512) are data payload.
FlowNet interoperates with Ethernet through a simple bridge device. To convert a FlowNet cell into an Ethernet frame, the bridge simply strips off the QoS extension. To go the other way, it generates a QoS extension with default or user-configured values. For example, the bridge could be programmed to give frames from certain workstations high priority, while frames from other workstations receive low priority.
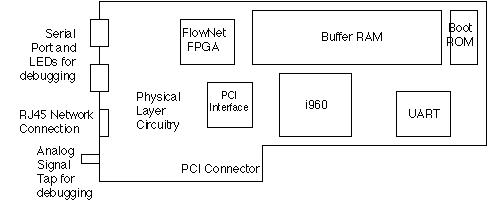
Figure 2. A diagram of the FlowNet prototype showing the location of the major components.
Distributed Switching
The FlowNet architecture is innovative in ways that go beyond the structure of the frame. A FlowNet network interface card (NIC) is quite simple, consisting of a transmitter, receiver, some memory and a microprocessor. NICs are logically daisy-chained together to form a loop. Physically, FlowNet uses a star topology with a hub, just like Ethernet. When a node sends a cell, the cell is received and retransmitted by every node between the transmitter and the receiver, an arrangement known as a store-and-forward loop. To reduce latency, FlowNet uses a technique called cut-through routing, which allows a cell to be retransmitted as soon as the header is received.
The resulting network is a switched network, with a unique feature: it does not require a switch. Instead, each NIC acts like a little two-port switch, with one port on the network and another at the host interface. Switching capability is distributed among all the nodes on the loop. Cell routing decisions are made in software by the on-board microprocessor, which provides sophisticated quality of service without expensive custom hardware.
Making cell-switching decisions in software is possible due to FlowNet’s large cell size. Cell-switching decisions are made on a per-cell basis. Larger cells mean fewer cells for a given data rate, which means fewer cell-switching decisions to be made. Current FlowNet prototypes can switch data at 250Mbps full-duplex (for a total data rate of 500Mbps) using an Intel i960 microprocessor.
Development
FlowNet is a state-of-the-art network. Beside being the fastest network available over 100-meter runs copper cable, it is the only network available that provides quality of service and is efficiently interoperable with Ethernet. FlowNet was developed on a shoestring budget (about $20,000 US for a dozen prototypes) by the authors working alone in their spare time.
Open-source software, including Linux and Intel’s gnu960 development tools, was instrumental in allowing this to happen. Linux was used to develop both the on-board firmware and the device drivers for FlowNet. Several Linux features were crucial for allowing us to meet our objectives. The first was the availability of model code for device drivers. Because FlowNet’s interface is so similar to Ethernet, we were able to use Donald Becker’s Tulip driver as a model and adapt it for FlowNet rather than starting from scratch.
The second Linux feature that helped immeasurably was kernel modules. Because device driver code is kernel code, it was not possible to run it as an application. Without modules, device drivers have to be tested by compiling them into the kernel and rebooting. This adds time to the development cycle. With kernel modules, kernel code can be dynamically linked and unlinked, reducing the testing cycle to less than a minute. We built a kernel module for FlowNet that loaded the card’s firmware through the PCI bus during initialization. This made it possible to recompile and restart all the FlowNet software with a single make command. As a result, all of the software for FlowNet was developed in less than three months.
The only time rebooting was necessary was when a bug in the driver code caused a kernel panic. Sometimes this would cause the machine to crash, but not always. At no time during the development process did we ever lose any data as the result of a kernel crash, despite the fact that on occasion we were overwriting critical kernel data structures with random bits. Linux is astoundingly robust.
Conclusions
FlowNet would not have come into being without Linux for a development platform. The hardware costs stretched our meager budget to the limit. The development tools needed to develop FlowNet for a commercial OS would have killed the project.
FlowNet was first conceived in 1993. Although Fast Ethernet (and soon, Gigabit Ethernet) seem to be taking over the world, FlowNet is still unique in offering gigabit performance and quality of service without requiring fiber optic cabling or discarding Ethernet infrastructure. Linux made it possible to build FlowNet as a private development—it almost certainly could not have happened any other way. FlowNet is not currently in production; contact the authors for more information (http://www.flownet.com/).